基于时间序列的异常检测算法小结
简介
搜罗了网上几乎所有的基于时间序列的异常检测方法,没有包括文献,整理记录一下。
综合引用以下文章:
- 数据挖掘导论
- 时间序列异常检测机制的研究
- KPI异常检测竞赛笔记
- 异常检测之时间序列的异常检测
- Skyline timeseries异常判定算法
- 腾讯蓝鲸数据平台之告警系统
- 异常点检测算法综述
- 时间序列简介(一)
时间序列预测
- 周期性:AE/VAE
- 稳定性:ARIMA
- 不稳定性:频谱分析/小波分析
RNN貌似对以上都适用。
异常检测
异常检测的方法有很多,根据《数据挖掘导论》,有以下几个分类:
基于模型的方法
许多异常检测技术首先建立一个数据模型。异常是那些同模型不能完美拟合的对象。例如,数据分布模型可以通过估计概率分布的参数来创建。如果一个对象不能很好地同该模型拟合,即如果它很可能不服从该分布,则它是一个异常。如果模型是簇的集合,则异常是不显著属于任何簇的对象。在使用回归模型时,异常是相对远离预测值的对象。
由于异常和正常对象可以看作两个不同的类,因此可以使用分类方法来建立这两个类的模型。当然,仅当某些对象存在类标号,使得我们可以构造训练数据集时才可以使用分类方法。此外,异常相对稀少,在选择分类方法和评估度量是需要考虑这一因素。
基于模型的方法又称为统计方法,主要通过拟合单个模型或多个模型来判断该点的概率。
1.单维情况
1.1 3σ-法则
(μ−3σ,μ+3σ)区间内的概率为99.74。所以可以认为,当数据分布区间超过这个区间时,即可认为是异常数据。
IQR是第三四分位数减去第一四分位数,大于Q3+1.5*IQR之外的数和小于Q1-1.5*IQR的值被认为是异常值。
- 1.3 Grubbs测试 Grubbs测试是一种从样本中找出outlier的方法,所谓outlier,是指样本中偏离平均值过远的数据,他们有可能是极端情况下的正常数据,也有可能是测量过程中的错误数据。使用Grubbs测试需要总体是正态分布的。 算法流程:
- 样本从小到大排序
- 求样本的mean和std.dev
- 计算min/max与mean的差距,更大的那个为可疑值
- 求可疑值的z-score (standard score),如果大于Grubbs临界值,那么就是outlier;
- Grubbs临界值可以查表得到,它由两个值决定:检出水平α(越严格越小),样本数量n,排除outlier,对剩余序列循环做 1-4 步骤。由于这里需要的是异常判定,只需要判断tail_avg是否outlier即可。
- 高维情况
- Mahalanobis距离
- X2 统计
- 单个/混合高斯分布
在某些情况下,很难建立模型,例如,因为数据的统计分布未知或没有训练数据可用。在这些情况下,可以使用如下所述的不需要模型的技术。
基于距离的方法/基于邻近度的方法
通常可以在对象之间定义邻近性度量,并且许多异常检测方法都基于邻近度。异常对象是那些远离大部分其他对象的对象。这一领域的许多方法都基于距离,称作基于距离的离群点检测方法。当数据能够以二维或三维散布图显示时,通过寻找与大部分其他点分离的点,可以从视觉上检测出基于距离的离群点。
但是该方法计算复杂度过高,且分布不均匀的点,容易出错。
方法:
- 基于角度的离群点检测 角度越小,说明距离越远。
- k-最近邻 到k-最近邻的距离。评分为数据对象与最近的k个点的距离之和。很明显,与k个最近点的距离之和越小,异常分越低;与k个最近点的距离之和越大,异常分越大。设定一个距离的阈值,异常分高于这个阈值,对应的数据对象就是异常点。
- Local Outlier Factor(LOF) LOF得分为数据对象的k个最近邻的平均局部密度与数据对象本身的局部密度之比。
- Connectivity Outlier Factor(COF) 如果点p的平均连接距离大于它的k最近邻的平均连接距离,则点p是异常点。COF将异常值识别为其邻域比其近邻的邻域更稀疏的点。
- stochastic outlier selection algorithm(无监督) 基于方差,近邻点越多,方差越小;近邻点越大,方差越大。
基于密度的方法
对象的密度估计可以相对直接地计算,特别是当对象之间存在邻近性度量时,低密度区域中的对象相对远离近邻,可能被看作异常。一种更复杂的方法考虑到数据集可能有不同密度区域这一事实,仅当一个点的局部密度显著地低于它的大部分近邻时才将其分类为离群点。
定义1:基于密度的异常
异常就是那些在低密度区域的数据对象,一个数据对象的异常分就是该对象所在区域的密度的倒数,下面是基于密度的异常分的计算公式:
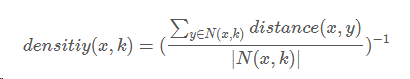
其中N(x,k)指的是x的k个最近的邻居的集合,|N(x,k)|表示该集合的大小,y是x最近的邻居。
定义2:给定半径的邻域内的数据对象数
一个数据对象的密度等于半径为d的邻域内的数据对象数。
d的选择很重要,若d太小,则会有很多正常的数据对象被认为是异常点;若d太大,则很多异常数据对象会被误判为正常点。事实上,当密度分布不均匀的时候,上述方法得到的异常点会不正确。为了克服密度不均匀的情况,我们使用下面的平均相对密度来作为异常分。
定义3:平均相对密度
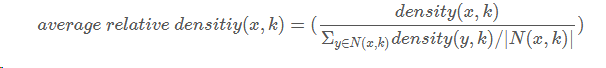

- 基于聚类的方法 一种利用聚类检测离群点的方法是丢弃远离其他簇的小簇。这种方法可以与任何聚类方法一起使用,但是需要最小簇大小和小簇与其他簇之间距离的國值。通常,该过程可以简化为丢弃小于某个最小尺寸的所有簇。这种方案对簇个数的选择高度敏感。此外,使用这一方案,很难将离群点得分附加在对象上。注意,把一组对像看作离群点,将离群点的概念从个体对象扩展到对象组,但是本质上没有任何改变。 一种更系统的方法是,首先聚类所有对象,然后评估对象属于簇的程度。对于基于原型的聚类,可以用对象到它的簇中心的距离来度量对象属于簇的程度。更一般地,对于基于目标函数的聚类方法,可以使用该目标函數来评估对象属于任意簇的程度。特殊情况下,如果删除一个对象导致该目标的显著改进,则我们可以将对象分类为离群点。如,对于K均值,脷除远离其相关簇中心的对象能够显著地改进簇的误差的平方和(SSE)。总而言之,聚类创建数据的模型,而异常扭曲模型。 基于划分的方法 孤立森林 基于划分的思想,划分成树,深度越低,说明越容易被划分,即为离群点。
- https://www.jianshu.com/p/4d817084a69a
- https://www.jianshu.com/p/5af3c66e0410
- http://www.cnblogs.com/fengfenggirl/p/iForest.html
- Principal Component Analysis(PCA) PCA在做特征值分解之后得到的特征向量反应了原始数据方差变化程度的不同方向,特征值为数据在对应方向上的方差大小。所以,最大特征值对应的特征向量为数据方差最大的方向,最小特征值对应的特征向量为数据方差最小的方向。原始数据在不同方向上的方差变化反应了其内在特点。如果单个数据样本跟整体数据样本表现出的特点不太一致,比如在某些方向上跟其它数据样本偏离较大,可能就表示该数据样本是一个异常点。
- Replicator Neural Networks(RNNs)
- AutoEncoder(AE):Anomaly Detection异常检测的几种方法
- Variational AutoEncoder(VAE):AIOps探索:基于VAE模型的周期性KPI异常检测方法
- Attribute Value Frequency 针对非数值型的数据,即类别离散数据的方法。
 上面的公式涉及到threshold和countnum两个参数,threshold如何获取我们将在下节进行介绍,而countnum可以根据的需求进行设置,比如对异常敏感,可以设置countnum小一些,而如果对异常不敏感,可以将countnum设置的大一些。 动态阈值 业界关于动态阈值设置的方法有很多,这里介绍一种针对360的lvs流量异常检测的阈值设置方法。通常阈值设置方法会参考过去一段时间内的均值、最大值以及最小值,我们也同样应用此方法。取过去一段时间(比如T 窗口)的平均值、最大值以及最小值,然后取max−avg和avg−min 的最小值。之所以取最小值的原因是让筛选条件设置的宽松一些,让更多的值通过此条件,减少一些漏报的事件。
上面的公式涉及到threshold和countnum两个参数,threshold如何获取我们将在下节进行介绍,而countnum可以根据的需求进行设置,比如对异常敏感,可以设置countnum小一些,而如果对异常不敏感,可以将countnum设置的大一些。 动态阈值 业界关于动态阈值设置的方法有很多,这里介绍一种针对360的lvs流量异常检测的阈值设置方法。通常阈值设置方法会参考过去一段时间内的均值、最大值以及最小值,我们也同样应用此方法。取过去一段时间(比如T 窗口)的平均值、最大值以及最小值,然后取max−avg和avg−min 的最小值。之所以取最小值的原因是让筛选条件设置的宽松一些,让更多的值通过此条件,减少一些漏报的事件。  窗口特征 统计特征 3-sigma 一个很直接的异常判定思路是,拿最新3个datapoint的平均值(tail_avg方法)和整个序列比较,看是否偏离总体平均水平太多。怎样算“太多”呢,因为standard deviation表示集合中元素到mean的平均偏移距离,因此最简单就是和它进行比较。在normal distribution(正态分布)中,99.73%的数据都在偏离mean 3个σ (standard deviation 标准差) 的范围内。如果某些datapoint到mean的距离超过这个范围,则认为是异常的。 z score 标准分,一个个体到集合mean的偏离,以标准差为单位,表达个体距mean相对“平均偏离水平(std dev表达)”的偏离程度,常用来比对来自不同集合的数据。 在模型中,z_score用来衡量窗口数据中,中间值的偏离程度。 算法流程:
窗口特征 统计特征 3-sigma 一个很直接的异常判定思路是,拿最新3个datapoint的平均值(tail_avg方法)和整个序列比较,看是否偏离总体平均水平太多。怎样算“太多”呢,因为standard deviation表示集合中元素到mean的平均偏移距离,因此最简单就是和它进行比较。在normal distribution(正态分布)中,99.73%的数据都在偏离mean 3个σ (standard deviation 标准差) 的范围内。如果某些datapoint到mean的距离超过这个范围,则认为是异常的。 z score 标准分,一个个体到集合mean的偏离,以标准差为单位,表达个体距mean相对“平均偏离水平(std dev表达)”的偏离程度,常用来比对来自不同集合的数据。 在模型中,z_score用来衡量窗口数据中,中间值的偏离程度。 算法流程:- 排除最后一个值
- 求剩余序列的平均值
- 全序列减去上面这个平均值
- 求剩余序列的标准差
- ( 中间三个数的平均值-全序列均值)/ 全序列标准差
- 样本从小到大排序
- 求样本的mean和std.dev
- 计算min/max与mean的差距,更大的那个为可疑值
- 求可疑值的z-score (standard score),如果大于Grubbs临界值,那么就是outlier;
 weighted moving average(加权移动平均)
weighted moving average(加权移动平均)  exponential weighted moving average(指数加权移动平均)
exponential weighted moving average(指数加权移动平均)  PS:https://www.jianshu.com/p/a2dbd47b3f1a double exponential smoothing(双指数平滑)
PS:https://www.jianshu.com/p/a2dbd47b3f1a double exponential smoothing(双指数平滑)
triple exponential smoothing(三指数平滑)(Holt-Winters)-
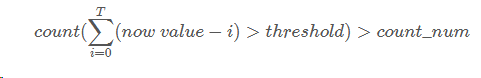 上面的公式涉及到threshold和countnum两个参数,threshold如何获取我们将在下节进行介绍,而countnum可以根据的需求进行设置,比如对异常敏感,可以设置countnum小一些,而如果对异常不敏感,可以将countnum设置的大一些。
上面的公式涉及到threshold和countnum两个参数,threshold如何获取我们将在下节进行介绍,而countnum可以根据的需求进行设置,比如对异常敏感,可以设置countnum小一些,而如果对异常不敏感,可以将countnum设置的大一些。  weighted moving average(加权移动平均)
weighted moving average(加权移动平均) 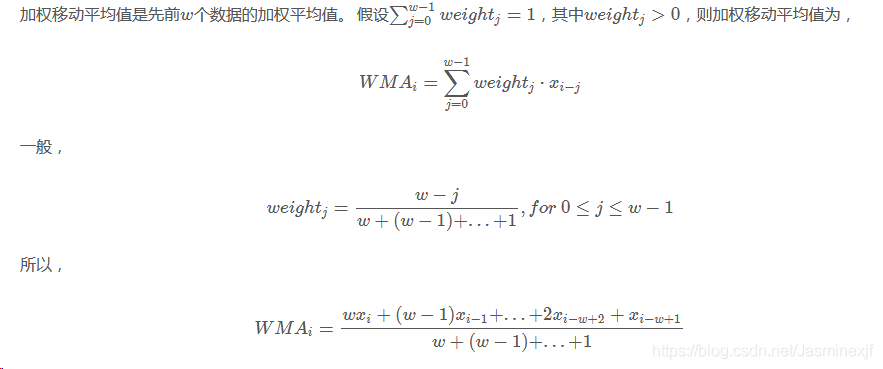 exponential weighted moving average(指数加权移动平均)
exponential weighted moving average(指数加权移动平均) PS:
PS:


stddev from moving average(移动平均-标准差)
先求出最后一个点处的指数加权移动平均值,然后再用最新的点和三倍方差方法求异常。
stddev from ewma(指数加权移动平均-标准差)
类似于特征3,不过在计算(t−mean)/std
时,使用的mean,std分别为对窗口数据进行移动加权平均后的平均值以及方差。
histogram bins
该算法和以上都不同,它首先将timeseries划分成15个宽度相等的直方,然后判断tail_avg所在直方内的元素是否<=20,如果是,则异常。
直方的个数和元素个数判定需要根据自己的metrics调整,不然在数据量小的时候很容易就异常了。
median absolute deviation(中位数绝对偏差)
median:大部分情况下我们用mean来表达一个集合的平均水平(average),但是在某些情况下存在少数极大或极小的outlier,拉高或拉低了(skew)整体的mean,造成估计的不准确。此时可以用median(中位数)代替mean描述平均水平。Median的求法很简单,集合排序中间位置即是,如果集合总数为偶数,则取中间二者的平均值。
median of deviation(MAD):同mean一样,对于median我们也需要类似standard deviation这样的指标来表达数据的紧凑/分散程度,即偏离average的平均距离,这就是MAD。MAD顾名思义,是deviation的median,而此时的deviation = abs( 个体 – median ),避免了少量outlier对结果的影响,更robust。
绝对中位差实际求法是用原数据减去中位数后得到的新数据的绝对值的中位数。
- 原数据-中位值=新数据
- 新数据的绝对值的中位数作为特征
mean subtraction cumulation(平均值减法累积?)
该特征类似于3-sigma准则。
算法流程
- 排除全序列(暂称为all)最后一个值(last datapoint),求剩余序列(暂称为rest,0..length-2)的mean;
- rest序列中每个元素减去rest的mean,再求标准差;
- 求窗口数据中间点到rest mean的距离,即 abs(last datapoint – rest mean);
first hour average(前若干-平均值)
和上述算法基本一致,只是比较对象不是整个序列,而是开始一个小时(其实这种这种思想可以推广,只要是时间序列刚开始的一段时间即可)的以内的数据,求出这段时间的均值和标准差和尾部数据(新产生的数据)用三倍方差的方法比较即可。
熵特征
为什么要研究时间序列的熵呢?请看下面两个时间序列:
时间序列(1):(1,2,1,2,1,2,1,2,1,2,…)
时间序列(2):(1,1,2,1,2,2,2,2,1,1,…)
在时间序列(1)中,1 和 2 是交替出现的,而在时间序列(2)中,1 和 2 是随机出现的。在这种情况下,时间序列(1)则更加确定,时间序列(2)则更加随机。并且在这种情况下,两个时间序列的统计特征,例如均值,方差,中位数等等则是几乎一致的,说明用之前的统计特征并不足以精准的区分这两种时间序列。
通常来说,要想描述一种确定性与不确定性,熵(entropy)是一种不错的指标。对于离散空间而言,一个系统的熵(entropy)可以这样来表示:
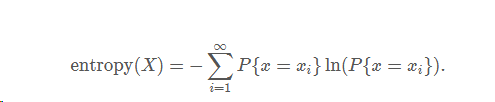
如果一个系统的熵(entropy)越大,说明这个系统就越混乱;如果一个系统的熵越小,那么说明这个系统就更加确定。
提到时间序列的熵特征,一般来说有几个经典的例子,那就是 binned entropy,approximate entropy,sample entropy。下面来一一介绍时间序列中这几个经典的熵。
Binned Entropy
从熵的定义出发,可以考虑把时间序列 XT
的取值进行分桶的操作。例如,可以把[min(XT),max(XT)]
这个区间等分为十个小区间,那么时间序列的取值就会分散在这十个桶中。根据这个等距分桶的情况,就可以计算出这个概率分布的熵(entropy)。i.e. Binned Entropy 就可以定义
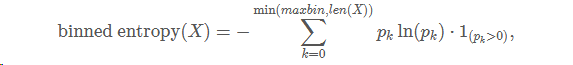
其中 pk表示时间序列 XT 的取值落在第 k 个桶的比例(概率),maxbin 表示桶的个数, len(XT)=T 表示时间序列 XT的长度。
如果一个时间序列的 Binned Entropy 较大,说明这一段时间序列的取值是较为均匀的分布在 [min(XT),max(XT)]
之间的;如果一个时间序列的 Binned Entropy 较小,说明这一段时间序列的取值是集中在某一段上的。
Approximate Entropy
回到本节的问题,如何判断一个时间序列是否具备某种趋势还是随机出现呢?这就需要介绍 Approximate Entropy 的概念了,Approximate Entropy 的思想就是把一维空间的时间序列提升到高维空间中,通过高维空间的向量之间的距离或者相似度的判断,来推导出一维空间的时间序列是否存在某种趋势或者确定性。那么,我们现在可以假设时间序列 XN:{x1,⋯,xN}的长度是 N ,同时 Approximate Entropy 函数拥有两个参数, m 与 r
,下面来详细介绍 Approximate Entropy 的算法细节。

Sample Entropy

分段特征
即使时间序列有一定的自相似性(self-similarity),能否说明这两条时间序列就完全相似呢?其实答案是否定的,例如:两个长度都是 1000 的时间序列,
时间序列(1): [1,2] * 500
时间序列(2): [1,2,3,4,5,6,7,8,9,10] * 100
其中,时间序列(1)是 1 和 2 循环的,时间序列(2)是 1~10 这样循环的,它们从图像上看完全是不一样的曲线,并且它们的 Approximate Entropy 和 Sample Entropy 都是非常小的。那么问题来了,有没有办法提炼出信息,从而表示它们的不同点呢?答案是肯定的。
首先,我们可以回顾一下 Riemann 积分和 Lebesgue 积分的定义和不同之处。按照下面两幅图所示,Riemann 积分是为了算曲线下面所围成的面积,因此把横轴划分成一个又一个的小区间,按照长方形累加的算法来计算面积。而 Lebesgue 积分的算法恰好相反,它是把纵轴切分成一个又一个的小区间,然后也是按照长方形累加的算法来计算面积。

之前的 Binned Entropy 方案是根据值域来进行切分的,好比 Lebesgue 积分的计算方法。现在我们可以按照 Riemann 积分的计算方法来表示一个时间序列的特征,于是就有学者把时间序列按照横轴切分成很多段,每一段使用某个简单函数(线性函数等)来表示,于是就有了以下的方法:
- 分段线性逼近(Piecewise Linear Approximation)
- 分段聚合逼近(Piecewise Aggregate Approximation)
- 分段常数逼近(Piecewise Constant Approximation)
说到这几种算法,其实最本质的思想就是进行数据降维的工作,用少数的数据来进行原始时间序列的表示(Representation)。用数学化的语言来描述时间序列的数据降维(Data Reduction)就是:把原始的时间序列 {x1,…,xN}用 {x′1,…,x′D}来表示,其中D<N。那么后者就是原始序列的一种表示(representation)。
分段聚合逼近(Piecewise Aggregate Approximation)—- 类似 Riemann 积分


至于分段线性逼近(Piecewise Linear Approximation)和分段常数逼近(Piecewise Constant Approximation),只需要在 x¯¯¯i
的定义上稍作修改即可。
符号逼近(Symbolic Approximation)—- 类似 Riemann 积分

- 总特征 总的训练特征为:时间窗口特征 + OneHot特征 + Timestamp所属的星期作为特征,label选取时间窗口中间点的标签。 因为选择了窗口数据的中间位置的点作为label值,所以在窗口移动过程中,在数据起始点和终结点会丢失 datasize-(windowsize/2) 个数据。(datasize为数据的总量,windowsize为时间窗口的大小) 在最终提交的结果中,缺失的数据点的预测结果,用0补充。 分类方法
- 随机森林
- XGBoost
- DNN
 算法组合 上面介绍了四种方法,这四种方法里面,SS和LS是针对非周期性数据的验证方法,而chain和CA是针对周期性数据的验证方法。那这四种方法应该如何选择和使用呢?下面我们介绍两种使用方法: 一、根据周期性的不同来选择合适的方法。这种方法需要首先验证序列是否具有周期性,如果具有周期性则进入左边分支的检测方法,如果没有周期性,则选择进入右分支的检测方法。 上面涉及到了如何检测数据周期的问题,可以使用差分的方法来检测数据是否具有周期性。比如取最近两天的数据来做差分,如果是周期数据,差分后就可以消除波动,然后结合方差阈值判断的判断方法来确定数据的周期性。当然,如果数据波动范围比较大,可以在差分之前先对数据进行归一化(比如z-score)。 二、不区分周期性,直接根据“少数服从多数”的方法来去检测,这种方法比较好理解,在此就不说明了。 其他方法 Smoothed z-score algorithm 主要思想:
算法组合 上面介绍了四种方法,这四种方法里面,SS和LS是针对非周期性数据的验证方法,而chain和CA是针对周期性数据的验证方法。那这四种方法应该如何选择和使用呢?下面我们介绍两种使用方法: 一、根据周期性的不同来选择合适的方法。这种方法需要首先验证序列是否具有周期性,如果具有周期性则进入左边分支的检测方法,如果没有周期性,则选择进入右分支的检测方法。 上面涉及到了如何检测数据周期的问题,可以使用差分的方法来检测数据是否具有周期性。比如取最近两天的数据来做差分,如果是周期数据,差分后就可以消除波动,然后结合方差阈值判断的判断方法来确定数据的周期性。当然,如果数据波动范围比较大,可以在差分之前先对数据进行归一化(比如z-score)。 二、不区分周期性,直接根据“少数服从多数”的方法来去检测,这种方法比较好理解,在此就不说明了。 其他方法 Smoothed z-score algorithm 主要思想:- 利用过去一段历史窗口针对下个节点值做预测(利用平均值,方差信息),若是其超过了一定的阈值,则是个异常点。
- 对异常点的数值进行平滑,以便评估下下个点是否为异常点。因为不做平滑,由于当前是个异常点,对平均值、方差影响较大,若是下一个点仍是异常点,可能不会识别。
- Time Series Decomposition: Yingying Chen, Ratul Mahajan, Baskar Sridharan, and Zhi-Li Zhang. A provider-side view of web search response time. In Proceedings of the ACM SIGCOMM 2013 confere nce on SIGCOMM, pages 243–254. ACM, 2013.
- Holtwinters: He Yan, Ashley Flavel, Zihui Ge, Alexandre Gerber, Daniel Massey, Christos Papadopoulos, Hiren Shah, and Jennifer Yates. Argus: End-to-end service anomaly detection and localization from an isp’s point of view. In INFOCOM, 2012 Proceedings IEEE, pages 2756–2760. IEEE, 2012.
- AutoEncoder(AE):Anomaly Detection异常检测的几种方法
- Variational AutoEncoder(VAE):AIOps探索:基于VAE模型的周期性KPI异常检测方法
- 静态阈值: Amazon cloudwatch alarm.
- Moving Average: David R. Choffnes, Fabián E. Bustamante, and Zihui Ge. Crowdsourcing service-level network event monitoring. In Proceedings of the ACM SIGCOMM 2010 Conf.
- Weighted Moving Average: Balachander Krishnamurthy, Subhabrata Sen, Yin Zhang, and Yan Chen. Sketch-based change detection: methods, evaluation, and applications. In Proceedings of the 3rd ACM
SIGCOMM conference on Internet measurement, pages 234–247. ACM, 2003. - Exponentially Weighted Moving Average: Balachander Krishnamurthy, Subhabrata Sen, Yin Zhang, and Yan Chen. Sketch-based change detection: methods, evaluation, and applications. In Proceedings of the 3rd ACM SIGCOMM conference on Internet measurement, pages 234–247. ACM, 2003.
- ARIMA: Yin Zhang, Zihui Ge, Albert Greenberg, and Matthew Roughan. Network anomography. In Proceedings of the 5th ACM SIGCOMM Conference on Internet Measurement, IMC’05, pages 30–30, Berkeley, CA, USA, 2005. USENIX Association.
- 时间序列的自回归模型—从线性代数的角度来看
- Extreme Value Theory: Siffer A, Fouque P A, Termier A, et al. Anomaly Detection in Streams with Extreme Value Theory[C]//Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, 2017: 1067-1075.
- Wavelet: Paul Barford, Jeffery Kline, David Plonka, and Amos Ron. A signal analysis of network traffic anomalies. In Proceedings of the 2nd ACM SIGCOMM Workshop on Internet measurment, pages 71–82. ACM, 2002.
- Fernando Silveira, Christophe Diot, Nina Taft, and Ramesh Govindan. Astute: Detecting a different class of traffic anomalies. In Proceedings of the ACM SIGCOMM 2010 Conference, SIGCOMM ’10, pages 267–278. ACM, 2010.
- Anukool Lakhina, Mark Crovella, and Christophe Diot. Mining anomalies using traffic feature distributions. In Proceedings of the 2005 Conference on Applications, Technologies, Architectures, and Protocols for Computer Communications, SIGCOMM ’05, pages 217–228. ACM, 2005.
- Anukool Lakhina, Mark Crovella, and Christophe Diot. Diagnosing network-wide traffic anomalies. In Proceedings of the 2004 Conference on Applications, Technologies, Architectures, and Protocols for Computer Communications, SIGCOMM ’04, pages 219–230. ACM, 2004
sklearn.covariance.EllipticEnvelope(高斯分布的协方差估计)sklearn.ensemble.IsolationForest(随机森林)sklearn.neighbors.LocalOutlierFactor(LOF)
- 负样本稀少:负样本过采样
- 缺失值:一阶线性插值填充、均值填充
- 样本权重:增加头部异常样本的权重
- KPI三种形态:周期波动/稳定/不稳定(进行聚类:裴丹18论文)
- 异常值替换:格拉布斯准则剔除替换
- 归一化/正则化:z-score、min-max
- 长异常区间只取前8个时间点
- 统计特征:均值、方差等
- 对比特征:差分、变分等
- 频域特征:频谱分析、小波分析等
- 拟合特征:移动平均、查分平均、权重平均等
- 原始特征
- 深度特征:AR+[LSTM、Seq2Seq]、AttentionLSTM+CNN
- 其他特征:Seasonal Trend Decomposition、PID(P:误差的值、I:误差的积分值、D:误差的微分值)、tsfresh抽取
- DNN+Threshold
- LR+小波分析+随机森林+BiLSTM,加权投票
- xgb

</div>